

クリタマです。
統計シリーズ、今回は
「対応のないt検定」について掘り下げていきましょう。
※ちなみに、この記事で扱っている計算の答えは間違っているようなので、ご自身で計算し直すことをお勧めします。
たぶんこのT値の計算式は(実測の平均値の差=10.4)/(平均の差の標準誤差=10.5779)かな?と思いました。どうやっても0.983にはならないので…笑
引用:社会と人に関わるヒント コメントより
他のエントリ、めちゃくちゃ参考になってます。更新楽しみにしてますー。
対応のないt検定とは
まず、「対応のない」というのは、「個人間(グループ間)での比較」という意味で、t検定は、「平均の差を調べること」だと言える。したがって、「個人間(グループ間)での平均値の差を比較する検定」が、これすなわち「対応のないt検定」ということである。
具体的に考えてみる
ここに、日本全国で行われた英語テスト結果を母集団として、そこからひっぱてきたサンプルがあります。(※架空データです)
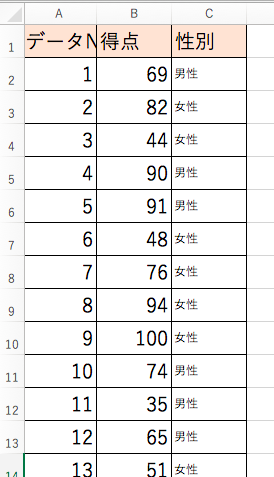
これを使って「対応のないt検定」について考えてみたいのですが、「対応のないt検定」は「グループ間での比較をするテスト」でしたよね?
ということは、「どういったグループ間で比較をするのか?」ということをまず考える必要があります。
今回は、「男性グループ」と「女性グループ」の間で比較をすることにしよう。
したがって、ここでの帰無仮説は
- 「男性と女性の英語テストの平均得点に差はない」
ということになります。
これにより対立仮説は
- 「男性と女性の英語テストの平均得点に差はある」
と決まります。
これすなわち、「英語テストを受けた男性」という母集団と、「英語テストを受けた女性」という母集団を、独立させて考えるということになる。
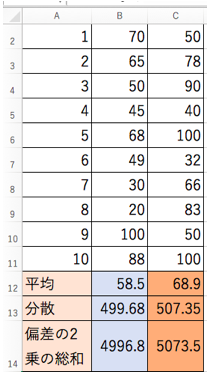
以下は、「男性の母集団」からサンプル数10として抽出された標本と、「女性の母集団」からサンプル数10として抽出された標本をデータとしてまとめたもの。(架空データです)
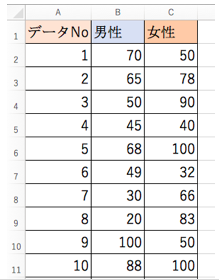
それぞれの平均を求める
では、
このデータを使って「対応のないt検定」を行うためには、次に何をする必要があるでしょうか?
「t検定」は「平均の差」に意味があるかどうかを調べる方法でした。
ということは、それぞれの標本の平均を計算する必要があります。
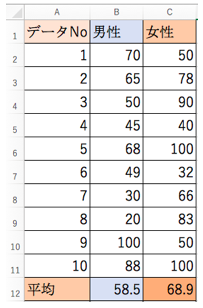
- 男性・・・58.5点
- 女性・・・68.9点
となりました。
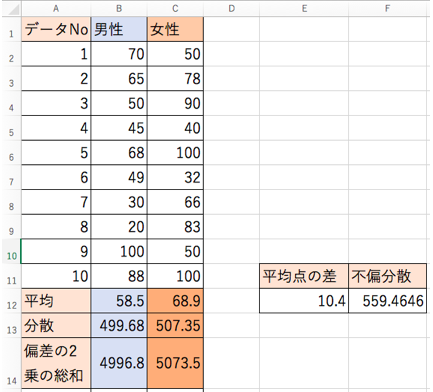
平均の差を求める
これで、各母集団から得られたサンプルにおいて、平均値を算出することができました。
「T検定」は「平均の差」に「意味があるかどうか」の検定ですから、当然僕らが次にすべきことは、「差を求める」という作業です。
今回は、女性の平均点>男性の平均点なので、以下のように計算します。
(ややこしくなければ、男性-女性でも構いません)
- 女性の平均点-男性の平均点
- 68.9-58.5
平均点の差は「10.4」点となります。
信頼区間を求めたい
続いて、t分布で解説した時と同様に
- サンプルをとる
- 平均点の差を計算する
- これを繰り返す
- 平均点の差のデータでヒストグラムを作る
という作業をすると、これがt分布に近づくということになります。
t分布はなぜ求めるのか?
というと、それは「標準誤差」を求める必要があるからです。
そして、標準誤差は「信頼区間の計算」に必要でした。
- 信頼区間=標本平均±t×標準誤差
信頼区間というのは、「母平均が含まれるであろう範囲」のことですよね?
つまり、今回は、「t検定における信頼区間」なのだから、「母集団同士の平均の差が含まれるであろう範囲」を求めるということになります。
そのために、「標準誤差」が必要ということなのです。
じゃあ、標準誤差はどうやって求めるの?
この結論は、平均の差のt分布の分散を計算して、そこからt分布の標準偏差、つまり標準誤差を求めます。
「それぞれの母集団」に関するt分布において、その分散を求める場合の公式は
- 不偏分散÷サンプルサイズ
でしたね?
わからない方は↓↓を参照のこと

信頼区間の求め方がよくわからないので実際にやってみることにした
やまだです。 前回のエントリで、信頼区間とははなにか? という話をしてまいりました。 そこで、このエントリ…
human-relation.net

2020-04-16 12:09
では、平均の差のt分布の分散はどのような計算になるのでしょうか?
これは、独立した母集団のt分布の分散を合算することで求められます。
つまり
- (男性テストのt分布の分散)+(女性テストのt分布の分散)
ということなので、これを変換すると
- (不偏分散÷サンプルサイズ)+(不偏分散÷サンプルサイズ)
となります。
。これが求められれば、あとは、この√が標準誤差なわけですね。
この辺の解説がわからない方は、↓↓分散と標準偏差を参照のこと

【明日から説明できる】分散とは何か?できるだけわかりやすく解説してみた
こんにちは、やまだです。 最近は、周りから、「まるで心理士みたいだね」と言われます。 心理士です。(ヒロシ風) …
human-relation.net

2020-03-28 12:20
式を整理すると
先ほどの公式をもう少し整理しておくと
- 不偏分散×(1/男性データ数+1/女性データ数)
ですから、この√が今回求めたい「標準誤差」というわけです。
で、次に、問題となってくるのが、「不偏分散」はどうやって求めたらええのよ?
ということですね。
これも母集団が単一の時に標本から不偏分散を求める流れと同様で
- (偏差の二乗の総和)÷(データ数-1)
この計算を足し合わせるということですね。
つまり
- (偏差の二乗の総和)÷男性データ数-1+ (偏差の二乗の総和)÷(女性データ数-1)
ということになります。
しがたって、全体の流れとしては、
- 信頼区間を求めるために「標準誤差」を求める
- 標準誤差を求めるために「不偏分散」を求める
- 不偏分散を求めるために「偏差の2乗の総和」と求める
- 偏差の2乗の総和を求めるために「標本分散」を求める
という流れりなりましょう。
百聞は一見に如かずです。実際に計算してみます。
標本分散を求める
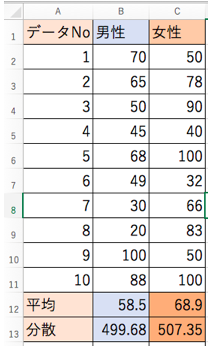
以下は先ほどのデータの続きですが、「varp関数」を使ってそれぞれの分散を求めます。
- 男性・・・499.68
- 女性・・・507.35
という値が算出されました。
偏差の2乗の総和を求める
分散は、偏差の二乗の総和の平均でしたね?
ということは、分散の値にデータ数を掛けることで求められます。
今回は、データ数「10」なので、先ほどの分散の値を10倍すればいいだけです。
すると、こうなりますね。
- 男性・・・4996.8
- 女性・・・5073.5
データ数がそれぞれ「10」なので、小数点が1つ右にずれだだけです。
で、この値を足し合わせたものが、先ほどの公式(不変分散を求める公式)の「分子」に該当します。
不偏分散を求める
一方、先ほどの公式(不偏分散を求める)の「分母は」それぞれの「データ数-1」の値を足し合わせたものです。
男性にしろ女性にしろデータ数は「10」ですから、
- 9+9=18
となりますね?
つまり、「18」が「分母」です。
ということは、(4996.8+5073.5)÷18を計算すればいいのです。
結果は
- 不偏分散・・・559.4646
でした。
※↑のフォーマットが欲しい方はこちらから
これで、標準誤差を求めることができます。
標準誤差を求める
標準誤差を求める公式は
- 不偏分散×(1/男性データ数+1/女性データ数)
の平方根(√)です。
よって
- 559.4646×(1/10+1/10)
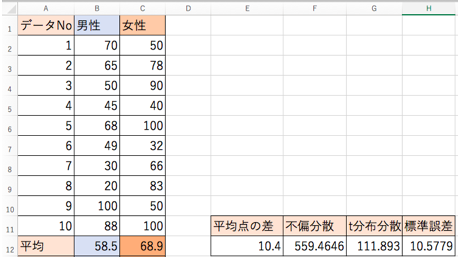
をまず、計算します。これがt分布の分散でもあります。
- t分布の分散・・・・111.893
となりました。これの√が標準誤差なので
- 標準誤差・・・10.6
という結果になります。
信頼区間を求める
これでいよいよにより、信頼区間を計算することができます。
やっと以下の公式にもどってきましたね。
- 信頼区間=標本平均±t×標準誤差
ここでは
- 標本平均-t×標準誤差
- 標本平均+t×標準誤差
の2つを計算します。この範囲が信頼区間になるからです。
一方、tはというと、t分表を確認しましょう。
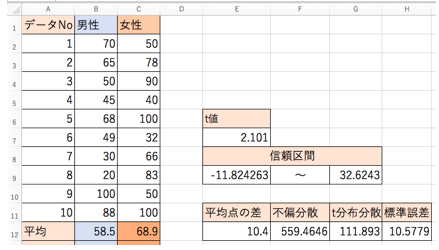
今回の自由度は、「18」ですから、「2.101」が今回のt値です。
したがって
- 10.4-2.101×10.5779
- 10.4+2.101×10.5779
を計算し
- 信頼区間・・・「-11.82〜32.62」
となります。
この場合、今回の標本から得られた平均の差は、「10.4」なので、この信頼区間内に含まれます。
結論
以上の結果から、「帰無仮説を棄却する」という結論にはいたらず、今回えられた「10.4」という数字に「性別による英語テストの点数に差がある」とは言えないことになるのです。
t検定をやってみる
では、これをいよいよt検定で解釈することにしましょう。
ここまでは、信頼区間を使っての解釈ということでした。
そもそも何が違うの?と思うかもしれませんが、「標準化されているか否か」という点で違いがあります。
- t検定・・・標準化されている(平均値を0とする)
- 信頼区間・・・標準化されていない(現実値に即している)
とはいえ
「それじゃあ、お前、最初からt検定でやれや!詐欺やん!」
という声が聞こえてくるかもしれませんが、まあ聞いてください。
実は、このt検定でこの「10.4」という平均の差に意味があるかどうかを検証するために、信頼区間を出す過程の中で必要な情報があったのです。
それが、「標準誤差」なのですね。
実際に対応のないt検定をやってみる
ではどのようにして、t検定でこの「10.4」という「平均の差」が意味のあるものかどうかを検討するのでしょうか?
全体の流れとしては
- 自由度からt値を調べる
- T値を求める(t÷標準誤差)
- ±tの範囲にT値が含まれるかどうかを検討する
- 「T<- t」あるいは「T>t」であれば、帰無仮説を棄却し、「-t≦T≦t」であれば、帰無仮説を棄却しない
以上、4フェーズですね。
では、先ほどの「英語テスト」のサンプルを使い、考えてみましょう。
自由度からt値を調べる
①の自由度からt値を調べるということについては、すでに行なっていますね。
自由度は「18」であり「t値」は「2.101」でした。
つまり、「-2.101〜2.101」の範囲が帰無仮説の非棄却ということになります。
では、次にT値を求めます。
- T=t値÷標準誤差
- 2.101÷10.577
です。これを計算すると
「0.983」となります。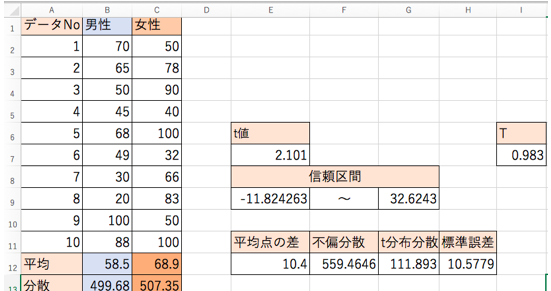
ちなみに、「T値ってなんだゴラァ(´Д` )」
という方がいるかもしれませんが、これは「サンプルの標準化」を行った時に、この「10.4」という平均の差が「平均の差の平均(つまり「0」という値)」に対してどこに位置するのかということを把握するための値のことです。
T値が±tの範囲に含まれるか否かを検証する〜これこそがt検定〜
では、3、4番目の手続きとして、このTが±tの範囲に含まれるか検証します。
- ±t・・・・ 「-2.101〜2.101」
- T値・・・「0.983」
それぞれの値は、上述の通りなので、T値は±tの範囲に含まれます。
と、いうことは、T値「0.983」ということは、十分起こりうるということがわかります。
よって、「帰無仮説は棄却できない」結果になり、「男女において英語テストの成績に差がある」とは言えないということになります。
この結論は、先ほどの「信頼区間による解釈」と同じですよね?
以上が、t検定による解釈になります。
t検定のレポート作成におこまりですか?
こちらの記事をご覧の方は、もしかしたら、t検定のレポートに追われている方が多いかもしれません。
僕自身も、過去の経験から気持ちよはよくわかります(笑)
そんな方のために、僕が作成したレポートを残しました。
↓↓必要であれば、ご参考ください(^^ゞ

本記事作成にあたっての参考書
①p値とは何か

②統計学がわかる

③やさしく学ぶ統計の教科書

④よくわかる心理統計



コメント
パスワードありがとうございます。心理学初学者でレポートに苦戦しております。またよろしくお願い致します。
>さちこさん
こちらこそよろしくお願いします。
レポート頑張ってください!